
Hoy Hablamos Sobre
Definición de AGI : cómo medir la inteligencia artificial general y por qué importa
por expertos internacionales
AGI no es ciencia ficción: cómo medir la inteligencia artificial general y por qué importa
Hasta hace poco, hablar de inteligencia artificial general (AGI, por sus siglas en inglés) sonaba a titulares lejanos. Hoy, con modelos como GPT-4 y GPT-5 avanzando rápido, se hace urgente definir qué entendemos por “inteligencia general” en máquinas. La confusión no es trivial: lo que medimos condiciona cómo regulamos, qué riesgos anticipamos y qué gobernanza diseñamos. Una definición rigurosa importa tanto como su código fuente.
AGI: ni vaga promesa ni solo benchmark
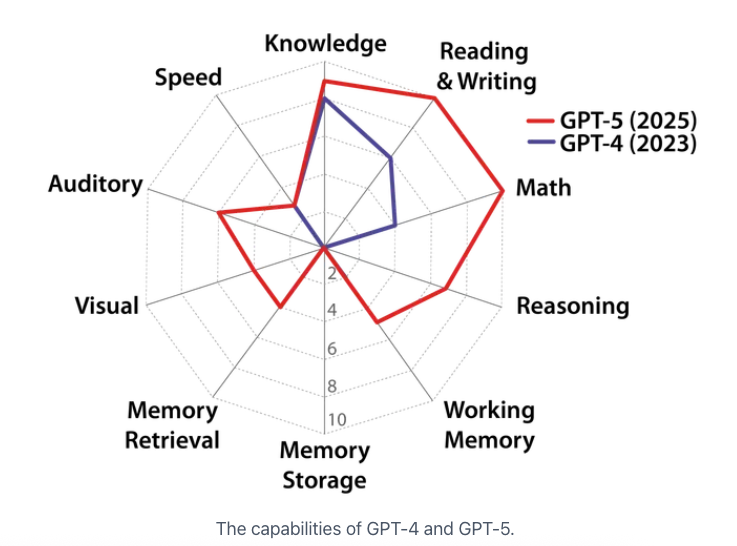
El nuevo informe “A Definition of AGI”, liderado por el Center for AI Safety junto a figuras como Dan Hendrycks, Yoshua Bengio o Max Tegmark, propone un marco cuantificable para definir AGI. Su método no se basa en titulares ni en benchmarks aislados, sino en psicometría cognitiva humana validada. Es decir, estructura qué debe saber hacer un sistema AGI según diez dominios de inteligencia sacados del modelo Cattell–Horn–Carroll, usado habitualmente por psicólogos y pedagogos.
Diez dominios cognitivos clave
- Razonamiento inductivo y deductivo
- Comprensión verbal
- Memoria a largo plazo
- Percepción visual y auditiva
- Capacidad de planificación ejecutiva
- Resolución de problemas novedosos
- Capacidades de aprendizaje autónomo
- Flexibilidad cognitiva
- Coordinación motora y sensoriomotora
- Conocimiento adquirido contextualizado
Esta estructura permite puntuar a los modelos de IA actuales según un estándar más humano: según el informe, GPT-4 alcanza 27% de la escala AGI, mientras que GPT-5 sube al 58%. Son avances significativos, pero aún están lejos del “nivel adulto bien educado” propuesto como umbral mental.
Oportunidades: medir mejor, regular mejor
Un marco como este permite alinear capacidades técnicas con exigencias legales. En especial, refuerza zonas grises del AI Act europeo, que todavía evita definir AGI. También dialoga con marcos de evaluación promisorios como el NIST AI Risk Management Framework en EE. UU., que promueve mediciones transparentes y replicables de riesgos.
Al utilizar métricas inspiradas en la inteligencia humana, el nuevo marco tiene implicaciones éticas claras. Permite responder con más precisión a preguntas como: ¿hasta qué punto un sistema puede tomar decisiones sin supervisión? ¿Qué significa hablar de “agencia” o “autonomía” en estas IAs? Las respuestas técnico-regulatorias requieren diagnósticos confiables, no inscripciones de marketing.
Riesgos: una inteligencia dispareja y opaca
El informe revela un patrón preocupante: los sistemas actuales tienen un perfil "cognitivo" desequilibrado. Son fuertes en tareas lingüísticas y de conocimiento factual, pero débiles en memoria de largo plazo, razonamiento general o coordinación de ideas complejas. Esta “inteligencia desigual” aumenta el riesgo de usar estas tecnologías más allá de sus límites reales, confundiendo especialización con generalidad.
“Los modelos actuales muestran una sobrespecialización en algunos dominios cognitivos mientras fallan en otros críticos. Esta asimetría representa un obstáculo para alcanzar una inteligencia verdaderamente general.” — Hendrycks et al., 2025
Esta falsa apariencia de competencia refuerza el riesgo de antropomorfismo técnico: usuarios, instituciones y empresas tienden a asumir que estos sistemas “entienden” más de lo que realmente procesan. Sin mecanismos de evaluación finos, la gobernanza se sostiene sobre estimaciones erróneas. Esto afecta, por ejemplo, al definir niveles de autonomía en aplicaciones críticas, como justicia, salud o defensa.
Casos destacados: evaluaciones más allá del benchmark
Los autores adaptan pruebas psicométricas humanas para testear modelos de IA. Este enfoque recuerda, en parte, a los debates sobre pruebas como el “Turing Test”, pero va más allá: se enfoca no en engañar al interlocutor, sino en medir capacidades cognitivas reales. Así, el enfoque se aproxima más a las evaluaciones usadas hoy en educación, psicología o neurodesarrollo.
Este tipo de batería ha empezado a interesar a instituciones como la OCDE, que promueve marcos para “IA comprensibles y transparentes”. También conecta con nuevos proyectos ISO/IEC sobre estándares de rendimiento y atribución funcional en IA avanzada.
Propuestas de acción desde la política pública
- Incluir mediciones de inteligencia general funcional en las evaluaciones de alto riesgo del AI Act y leyes nacionales de IA.
- Impulsar auditorías independientes que usen métodos psicométricos estandarizados para validar afirmaciones sobre AGI.
- Exigir disclosure transparente de debilidades cognitivas identificadas en modelos avanzados implantados en servicios críticos.
- Invertir en capacidades técnicas públicas para testear sistemas de IA con criterios empíricos comparables al rendimiento humano.
- Fomentar marcos internacionales como el propuesto por el informe para evitar fragmentación regulatoria.
¿Qué inteligencia queremos replicar?
Hablar de AGI ya no es ciencia ficción. Tampoco es trivial. Si modelos como GPT-5 ya se acercan al 60% del “nivel adulto” en ciertas tareas, urge reforzar la gobernanza antes de que las capacidades lleguen por sorpresa. No conviene apresurar definiciones, pero sí construirlas desde evidencia, diversidad de saberes e interés público.
¿Qué tipo de inteligencia deberíamos querer en máquinas que actúan en nuestras sociedades? ¿Una que solo acumule conocimiento o una que también comprenda límites, contexto y consecuencias humanas?
Suscríbete a mi newsletter para explorar las claves prácticas de una inteligencia artificial responsable y pública.
Quieres aprender más sobre la IA Responsable y Gobernanza de la IA, mira los artículos de blog que he redactado para ti.
Para cualquier duda que puedas tener, me puedes mandarme email a info@karine.ai, con mucho gusto te contestaré.